Example 1: 从 hdfs 中查询
之前我所在的 team 将所有的 messages 保存在 mysql 中, 其中一种一天中写入的次数超过 30000000, 约 20G 大小. 对 mysql 的负担还是比较大的.
因此建立数据仓库, 将该种 messages 存储到 hdfs 中.
下面看一个用 Spark SQL 从 hdfs 中查询数据的 example:
$ ./bin/spark-shell --master spark://1.1.1.1:8080 --driver-memory 10g --conf spark.cores.max=20
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.1.0
/_/
Using Scala version 2.10.4 (OpenJDK 64-Bit Server VM, Java 1.6.0_24)
Type in expressions to have them evaluated.
Type :help for more information.
Spark context available as sc.
scala> val sqlContext = new org.apache.spark.sql.SQLContext(sc)
sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@19c50523
scala> val path = "/path/../20150417"
path: String = /path/../20150417
scala> val msg_0417 = sqlContext.jsonFile(path)
msg_0417: org.apache.spark.sql.SchemaRDD =
SchemaRDD[22] at RDD at SchemaRDD.scala:103
== Query Plan ==
== Physical Plan ==
ExistingRdd [cluster_id#13,cluster_status#14,host_address#15,host_id#16,hour#17,message_id#18,protocol#19,result#20,sequence#21,topic#22,user_host_id#23,user_id#24,user_task_id#25], MappedRDD[21] at map at JsonRDD.scala:38
scala> msg_0417.registerTempTable("msg_0417")
scala> msg_0417.printSchema()
root
|-- cluster_id: integer (nullable = true)
|-- cluster_status: boolean (nullable = true)
|-- host_address: string (nullable = true)
|-- host_id: integer (nullable = true)
|-- hour: integer (nullable = true)
|-- message_id: string (nullable = true)
|-- protocol: string (nullable = true)
|-- result: string (nullable = true)
|-- sequence: integer (nullable = true)
|-- topic: string (nullable = true)
|-- user_host_id: integer (nullable = true)
|-- user_id: integer (nullable = true)
|-- user_task_id: integer (nullable = true)
scala> sqlContext.sql("select * from msg_0417 where user_task_id = 54 and cluster_id = 3 and hour = 3").collect().foreach(println)
[3,true,http://site01.com,48,3,1429211040fdf3de6c9fe1,HTTP,{"task-time":238,"content-length":33931,"code":0,"parse-ip":"122.112.13.59","http-code":200,"dns-time":21,"host":"http:\/\/site01.com","backends":[],"connect-time":54,"time":238,"reason":0},1429210800,SLA,47,3,54]
[3,true,http://site02.com,48,3,14292116302ca30e65f3e0,HTTP,{"task-time":237,"content-length":33931,"code":0,"parse-ip":"122.112.13.59","http-code":200,"dns-time":20,"host":"http:\/\/site02.com","backends":[],"connect-time":52,"time":237,"reason":0},1429211400,SLA,47,3,54]
相比于 mysql, 有如下的优点:
- 可以很方便的在多天的数据中查询, 上面例子中的 path 是一个路径, Spark SQL 会自动加载目录下所有符合格式的文件.
- 查询时, 可以根据需要设置更多的 core.
缺点:
- 载入数据需要消耗较长的时间. 具体取决于 hdfs 的读取速度, 上面加载 20G 的数据用了约 4 分钟.
数据的读入
对 json 格式的支持: 如果一个文件中的每一行都是一个合法的 json 对象, 则 sqlContext.jsonFile() 可以加载该文件.
Spark SQL 组件
Spark SQL 组件图:
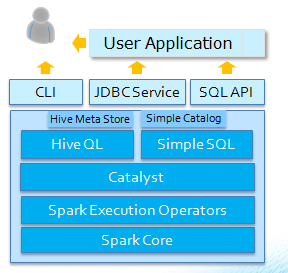
由上图可知 Spark SQL:
- 同时支持 HiveQL 和 Simple SQL 两种 SQL 方言.
- 基于 Spark Core, 如 RDD.
Spark SQL 架构
Spark SQL 架构图:
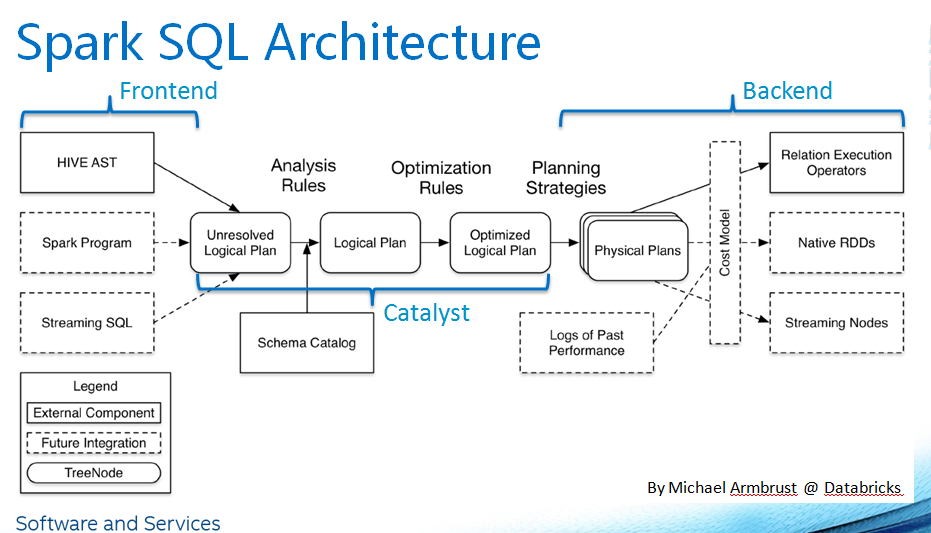
DataFrame
Spark SQL 中的数据组织成 DataFrame 的格式. DataFrame 在概念上和关系型数据库中的表是相同的.
DataFrame 可以从 RDD, Hive table, JSON 文件等数据源直接创建.
Schema
创建 DataFrame 需要先知道数据对象的 schema, Spark SQL 支持两种设置 schema 的方法:
- 使用反射来推断 RDD 中特定类型对象的 schema . (有适用范围, 当数据类型是一个 case class)
- 指定特定的 schema .
数据源
Spark SQL 通过 DataFrame 接口支持多种数据源:
- json: Spark SQL 自动推断 schema
- parquet: 读写时自动保存 schema 和 数据
- hive table: 支持从 hive table 中读写数据
- jdbc: 通过 jdbc 从其它的数据库读数据
列式内存存储
内存中数据表示的3种方法:
- 内存中直接缓存磁盘上序列化后的数据. 在查询时根据需求进行反序列化, 反序列化是瓶颈.
- 将数据分区作为 JVM 对象集合存储, 可以避免反序列化, 但占用空间较大. 大量的 JVM 对象同时会导致 JVM 的垃圾收集耗时严重.
- 列示内存存储, 每一列仅创建一个 JVM 对象, 可以带来快速访问, 垃圾收集和紧凑的数据表示。
分区统计和映射修剪
每个分区收集来的统计信息包含了每一个列的范围, 当不同值的个数较少的时候, 会包含所有不同的值. 所收集到的统计信息会被发送回驱动节点并存储在内存中, 在查询执行过程中用于修剪分区.
Catalyst
在 spark 上执行 sql 查询的步骤与传统的 RDBMS 类似: 查询解析, 生成逻辑计划和生成物理计划.
Catalyst 的作用是逻辑计划的生成和优化.
Catalyst essentially a extensible framework to Analyze & Optimize the logical plan, expression.
逻辑计划和物理计划:
- 都是表示查询求值的树.
- 逻辑计划是高层次, 代数表示的.
- 物理计划是低层次, 可实际执行的.
- 逻辑计划中的操作符和查询语言相关, 物理计划中的操作符对应访问数据函数的具体实现.
下面再看一下 HiveQL 和 Simple SQL 方言的 Catalyst 解析图:
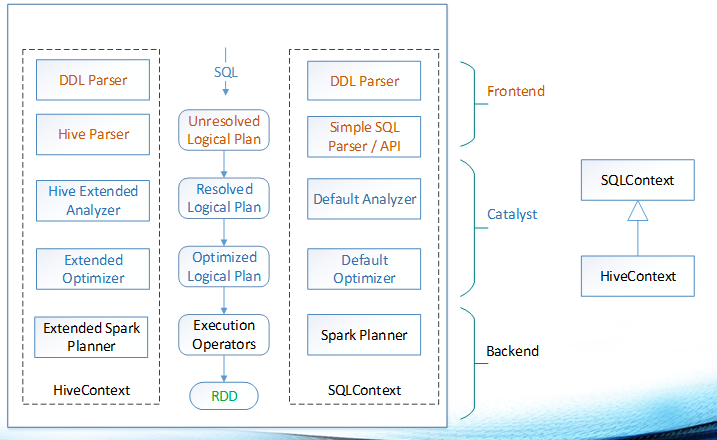
例如:
SELECT
a.key * (2 + 3), b.value
FROM T a JOIN T b
ON a.key=b.key AND a.key>3
的解析过程是:
# 解析 SQL Text 生成 Parsed Logical Plan
== Parsed Logical Plan ==
Project [('a.key * (2 + 3)) AS c_0#24,'b.value]
Join Inner, Some((('a.key = 'b.key) && ('a.key > 3)))
UnresolvedRelation None, T, Some(a)
UnresolvedRelation None, T, Some(b)
# Parsed Logical Plan 数据绑定和语法分析 生成 Analyzed Logical Plan
== Analyzed Logical Plan ==
Project [(CAST(key#27, DoubleType) * CAST((2 + 3), DoubleType)) AS c_0#24,value#30]
Join Inner, Some(((key#27 = key#29) && (CAST(key#27, DoubleType) > CAST(3, DoubleType))))
MetastoreRelation default, T, Some(a)
MetastoreRelation default, T, Some(b)
# 优化 Analyzed Logical Plan 生成 Optimized Logical Plan
== Optimized Logical Plan ==
Project [(CAST(key#27, DoubleType) * 5.0) AS c_0#24,value#30]
Join Inner, Some((key#27 = key#29))
Project [key#27]
Filter (CAST(key#27, DoubleType) > 3.0)
MetastoreRelation default, T, Some(a)
MetastoreRelation default, T, Some(b)
== Physical Plan ==
Project [(CAST(key#27, DoubleType) * 5.0) AS c_0#24,value#30]
BroadcastHashJoin [key#27], [key#29], BuildLeft
Filter (CAST(key#27, DoubleType) > 3.0)
HiveTableScan [key#27], (MetastoreRelation default, T, Some(a)), None
HiveTableScan [key#29,value#30], (MetastoreRelation default, T, Some(b)), None
优化后的逻辑计划中和物理计划中:
- 概念上的
Join Inner对应具体的实现BroadcastHashJoin. MetastoreRelation对应具体的HiveTableScan [key#...] MetastoreRelation.
Example 2: 在 stream 查询
// search in stream RDD
stream.foreachRDD(new Function2<JavaRDD<String>, Time, Void>() {
@Override
public Void call(JavaRDD<String> rdd, Time time) throws Exception {
DataFrame df = sqlContext.jsonRDD(rdd);
df.registerTempTable("tmp");
DataFrame searchResult = sqlContext.sql("select * from tmp where key < 7 and value > 90");
searchResult.toJavaRDD().foreach(new VoidFunction<Row>() {
@Override
public void call(Row row) throws Exception {
System.out.println(row.toString());
}
});
System.out.println(rdd.toString());
return null;
}
});
完整的 stream 中查询代码: SqlInStream.java
输出:
Generate rdds ...
Generate streaming...
[67902,2,93]
...
[52436,2,93]
[58080,3,96]
ParallelCollectionRDD[0] at parallelize at SqlInStream.java:50
[7103,5,91]
[86463,4,97]
...
[14470,2,93]
ParallelCollectionRDD[1] at parallelize at SqlInStream.java:50
数据备份
Spark Streaming 从一个或多个输入流开始执行. 系统加载数据流的方式:
- 直接从客户端接收记录数据. 如从 kafka 中读取.
- 周期性的从外部存储系统中加载数据, 如从 hdfs 中读取.
在第一种方式下, 由于D-Streams需要输入的数据被可靠地进行存储来重新计算结果,因此我们需要确保新的数据在向客户端程序发送确认之前,在两个工作节点间被复制。如果一个工作节点发生故障,客户端程序向另一个工作节点发送未经确认的数据。
基于数据分配计算
前面有提到过 分区统计和映射修剪, Spark driver 会有数据的统计信息, 任务分配是基于数据位置的, 尽量使计算和所需的数据最接近.
局部 DAG 执行
Spark SQL 在 stream 中查询未经历过一个数据加载过程的新数据. 这就排除了那些依赖精确数据统计的静态查询优化技术的使用, 例如通过索引维持的统计信息. 新数据统计的缺乏, 再加上 UFD (UserFile Directory)的普遍使用, 这就需要动态方法来进行查询优化.
在分布式环境中支持动态查询优化, 扩展了 spark 以支持局部 DAG 执行, 这是一项能够允许运行时收集数据统计信息进行动态地改变查询计划的技术.
内存管理
- 每个节点的块存储管理RDD的分片是以LRU(最近最少使用)的方式,如果内存不够会依LRU算法将数据调换到磁盘.
- 用户可以设置最大的超时时间,当达到这个时间之后系统会直接将旧的数据块丢弃而不进行磁盘I/O操作.
并行恢复
在大规模的情况下, 节点故障和慢任务会很常见, 会很大地影响程序的性能.
节点故障采用并行恢复机制.
当一个节点失败,D-Streams允许节点上RDD分片的状态以及运行中的所有任务能够在其它节点并行地重新计算。通过异步地复制RDD状态到其它的工作节点,系统可以周期性地设置RDDs状态的检查点.
如果一个节点失败了,系统会检查所有丢失的RDD分片,然后启动一个任务从上次的检查点开始重新计算。多个任务可以同时启动 去计算不同的RDD分片,使得整个集群参与恢复
简单点说, 就是: 某个节点失效时,集群中的各个节点都分担并计算出丢失节点RDD的一部分,从而使得恢复速度远快于上行流备份,且无复制开销。
推测执行
慢任务采用推测执行机制.
Spark 使用一个简单的阈值来检测较慢的节点:如果一个任务的运行时长比它所处的工作阶段中的平均值高1.4倍以上,就标记它为慢节点. 然后运行慢任务的备份副本.
Shark 和 Spark SQL
Spark SQL 的前身是 Shark, 至于区别可以参考下: Spark SQL 和 Shark 在架构上有哪些区别
应用场景
- 大规模, 分布式的数据查询, 分析
参考