Compare
| Feature | Spark Streaming | Storm |
|---|---|---|
| Latency | Few seconds | Sub-second |
| Data guarantee | Exactly once | At least once 1 |
| Process model | Batch | One |
| Fail recovery price | Low 2 | High 3 |
| Resource manager integration | YARN, Mesos | YARN, Mesos |
| Consistency break condition | Output operation failure | Replay an event |
| Popular 4 | More 5 | Less |
| Development cost | Less 6 | More |
| Batch framework integration | Spark | N/A |
| Message Passing Layer | Netty, Akka | Netty or ZeroMQ |
| Implement Language | Scala | Clojure |
| Hadoop distribution support | Hortonworks, Cloudera, MapR | Hortonworks, MapR |
| Company support | Databricks | N/A |
| Origin | Uc Berkeley | BackType, Twitter |
| Production use | 2013 | 2011 |
- Actually, Storm’s Trident library also provides exactly once processing. But, it relies on transactions to update state, which is slower and often has to be implemented by the user.
- Because of the dependency chain of Spark RDD, it’s easy to recovery from failure by relaying it from the source, need not to track every middle state.
- Each individual record has to be tracked as it moves through the system
- Judged by code commit velociy and issue velocity.
-
Spark also has a better ecosystem
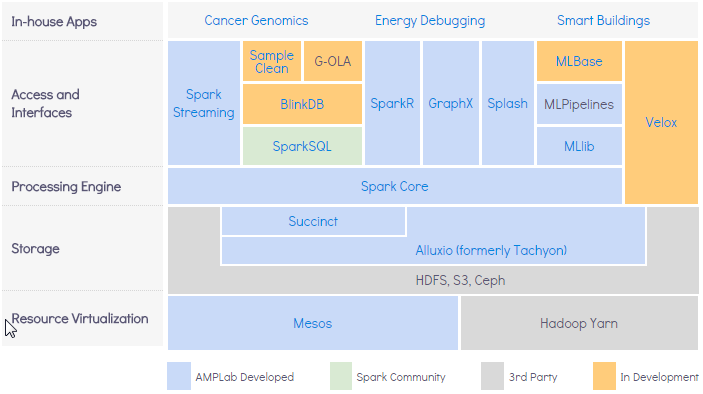
- With Spark, the same code base can be used for batch processing and stream processing.