The Log: What every software engineer should know about real-time data’s unifying abstraction is a very good article about data handle, but it’s too long to review. I record points which are important to me here.
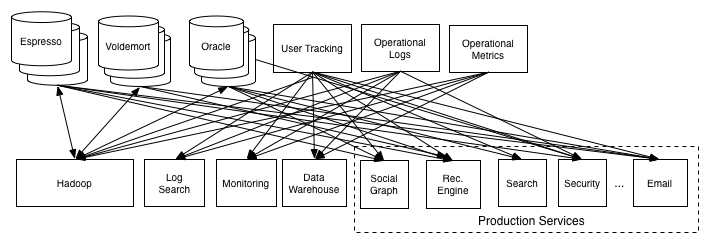
Usually we need to connect two components or modules to transfer data between them. A common way is just writing a simple script file to do this, by calling each component’s api or command line tool. But is clearly infeasible when we have dozens of data system to cooperation with each other. Connecting all of these will lead to building custom piping between each pair of systems something like this:
Instead we can unify all data pipelines like this:
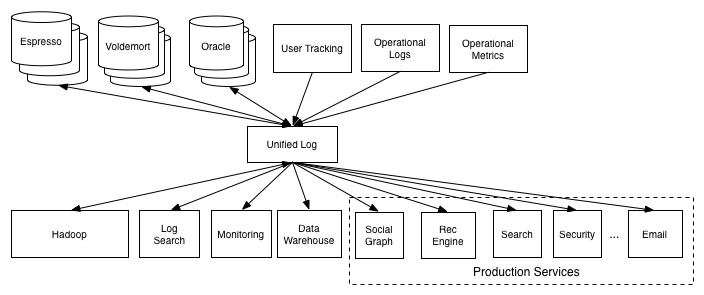
Here are some of the unifying structure’s advantages:
- Every component just need to connect the same pipeline in the same way, without worrying about different components’ api and address.
- Delopyment and operation are easier.
- Unlock a lot of possibilities for data usages.
- Tranditional ETL process can be done on a cleaner and more uniform set of streams.
- If we can unify the encoding format of all data in the central pipeline, it will reduce a lot work for encoding/decoding.
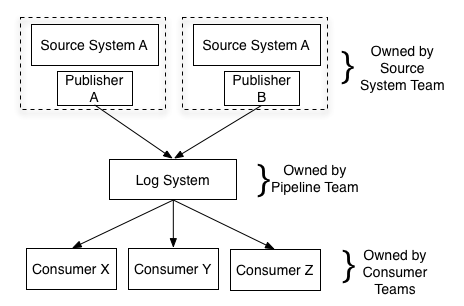
The suggested ownership of each component should like this: