Sometimes we may want to activate the spark.speculation option to speed up our job, but it may be dangerous. Why? Because part of our output/update actions may be duplicated, which may break data consistency.
Let’s show it by a simple test.
import org.apache.spark.{SparkConf, TaskContext}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Counts words in UTF8 encoded, '\n' delimited text received from the network every second.
*
* Usage: NetworkWordCount <hostname> <port>
* <hostname> and <port> describe the TCP server that Spark Streaming would connect to receive data.
*
* To run this on your local machine, you need to first run a Netcat server
* `$ nc -lk 9999`
* and then run the example
* `$ bin/run-example org.apache.spark.examples.streaming.NetworkWordCount localhost 9999`
*/
object NetworkWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: NetworkWordCount <hostname> <port>")
System.exit(1)
}
// Create the context with a 1 second batch size
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(30))
// Create a socket stream on target ip:port and count the
// words in input stream of \n delimited text (eg. generated by 'nc')
// Note that no duplication in storage level only for running locally.
// Replication necessary in distributed scenario for fault tolerance.
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" ")).repartition(5)
val wordCounts = words.map(x => {
if (TaskContext.getPartitionId() % 2 > 0) {
Thread.sleep(10000)
}
(x, 1)}
).reduceByKey(_ + _)
wordCounts.repartition(3).foreachRDD(
rdd => rdd.foreachPartition(
partition => {
var sleepFlag = false
if (partition.nonEmpty && TaskContext.getPartitionId() % 2 > 0) {
sleepFlag = true
}
partition.foreach(x => {
if (sleepFlag) Thread.sleep(10000)
System.out.println("TestMark: partition=" + TaskContext.getPartitionId() + ", value=" + x)
})
}
))
ssc.start()
ssc.awaitTermination()
}
}
Submit the upon class to YARN cluster(speculation is not available in local mode)
spark-submit --master yarn --conf spark.speculation.quantile=0.1 --conf spark.speculation=true --class NetworkWordCount target/tests-1.0-SNAPSHOT.jar hostname 9999
In the stages and tasks view, we can see that the speculation triggered.
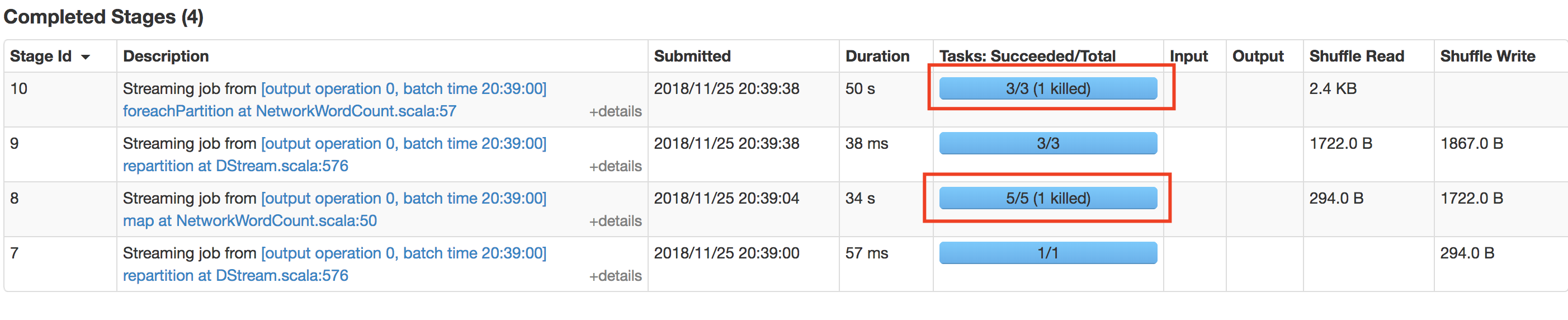

Then we check the stdout of each task and can find duplicate items

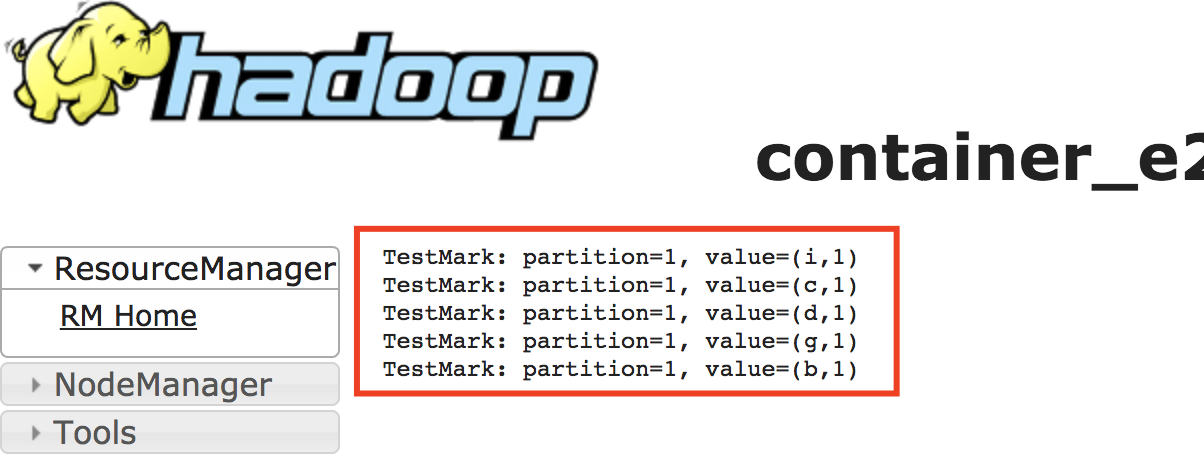
So, be careful about activating this option!
Refer
- How does Spark speculation prevent duplicated work?
- https://stackoverflow.com/questions/46375631/setting-spark-speculation-in-spark-2-1-0-while-writing-to-s3